Cosine Similarity as Logits?: A Scalable Knowledge Probe Using Embedding Vectors from Generative Language Models
There has been a growing interest in utilizing pre-trained language model (PLM) as a soft knowledge base. Knowledge probers evaluate PLM's ability to fulfil such role using relational knowledge stored in a knowledge graph (KG). However, knowledge probes for generative language models are slow, and do not scale over input size. To this end, we propose a fast and scalable knowledge probe for generative PLMs and demonstrating its ability to probe using KGs that were previously infeasible.
Mar 24, 2026
Cosine Similarity as Logits?: Few-shot Knowledge Graph Completion with Embedding Vectors of a Generative PLM and its Application in Knowledge Probing
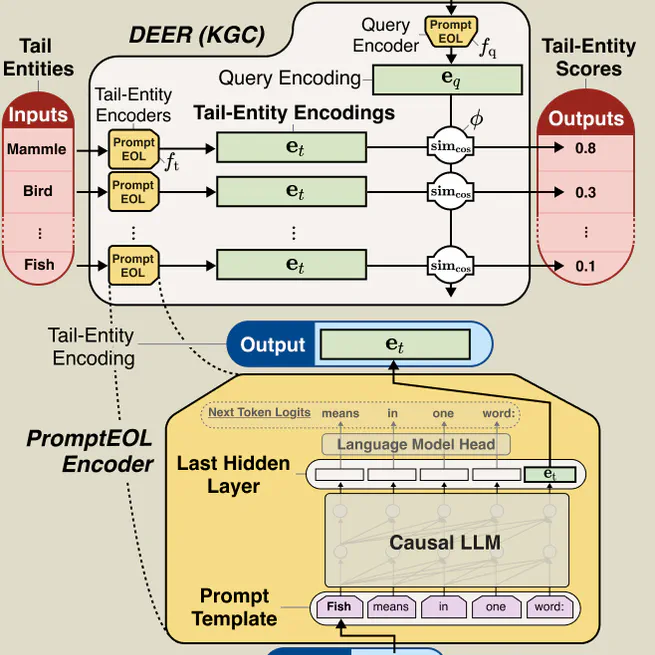
The Knowledge graph completion (KGC) task aims to predict missing relations in knowledge graphs (KGs). Recently, text-based KGC approaches have gained attention but they present challenges: encoder-based methods require fine-tuning making it non-ideal when an ideal KG for training cannot be obtained, such as when KG is sparse or predicting new relation-types. Meanwhile, decoder-based methods make prediction by generating tokens, where entity disambiguation becomes a challenge. KGC is also used in knowledge proving, which aims to evaluate the know edge retrieval capability of pre-trained language models (PLMs), but existing probes for generative PLM capable of ranking all multi-token and single-token entities are computationally inefficient. To address these problems, we propose DEER, an encoder-based few-shot KGC, leveraging a generative PLM that achieves a linear inference time complexity. Our experiment shows that DEER outperforms a fine-tuned KGC model in a relationally inductive setting and aligns with an existing knowledge-probing method, positioning it as a possible alternative.
Mar 10, 2025
科学技術文献における知識グラフ補完を用いた効率的な知識グラフの作成
近年、科学論文の増加に伴い、科学的知識の関係性を扱うための知識グラフのような統一された構造化資源の需要が高まっている。このような構造化資源の整備は、新しい科学的知識の発見などに繋がることがある。しかし、そのような資源を人手で作成するには、各科学分野の専門知識が必要であり、資源作成には高いコストがかかる。本研究では、知識グラフを対象に、既存の科学関係抽出データセットを拡張することで、科学分野に関する知識グラフを作成する。また、知識グラフ補完タスクを知識グラフのデータ拡張に応用することで、既存の知識グラフから事実に即した新しい科学的知識の関係が導出可能かを検証する。
Aug 13, 2024